Deepfake検出
自己教師あり学習を導入したWavelet Vision TransformerによるDeepfake検出の高精度化
Project Details
- Start : 2022.4
- Collaborator : 高瀬俊希
概要
近年,AIによって顔画像を巧妙に合成・加工するDeepfake技術が急速に進化しており,SNSやメディアなどで悪用される事例も増えています.このような背景から,Deepfake画像を高精度で自動検出する技術の開発が強く求められています.
本研究では,Deepfake検出における新たなアプローチとして,「Wavelet Vision Transformer(Wave-ViT)」に**自己教師あり学習(Self-Supervised Learning)**を組み合わせる手法を提案し,その有効性を検証しました.
提案手法
Wavelet Vision Transformer(Wave-ViT)の導入
従来のVision Transformer(ViT)は,画像全体の構造を捉える能力に優れているものの,高周波成分(境界線やノイズなど細部)の抽出が苦手で,Deepfake検出ではCNNより精度が劣る傾向がありました. そこで本研究では,画像を周波数成分に分解できるウェーブレット変換(Wavelet Transform)を取り入れたWave-ViTを採用しました.これにより,Deepfake画像に現れやすい高周波の偽造痕跡を効果的に捉えることが可能になります.
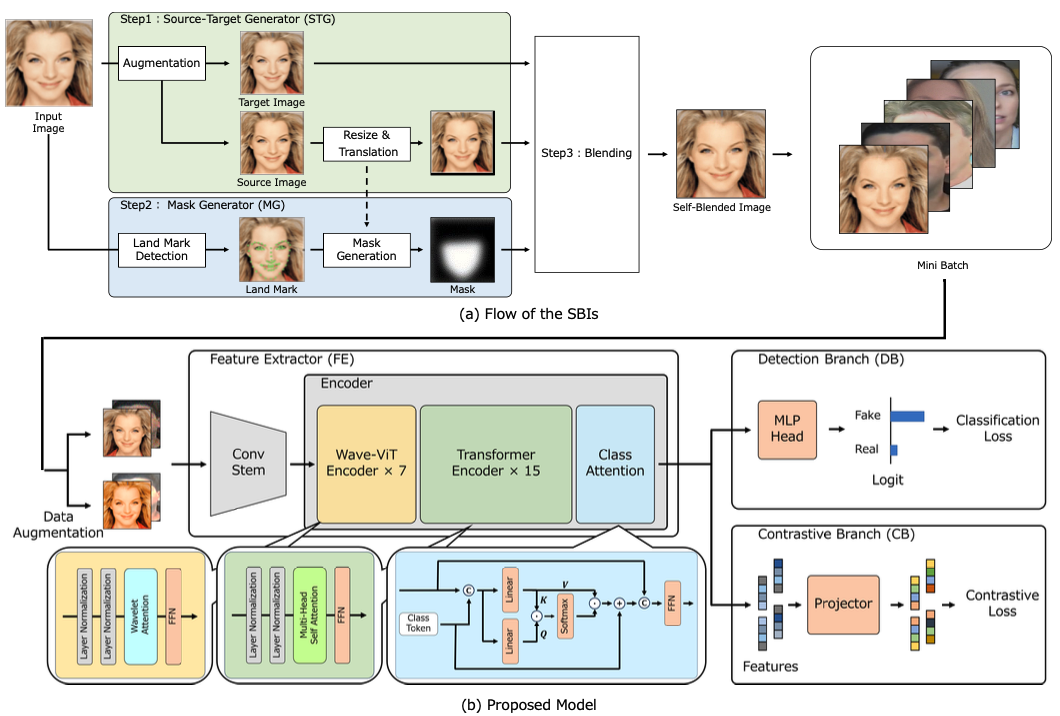
提案手法の流れ
自己教師あり学習(SimCLR)の導入
Deepfake画像と自然な画像の微細な違いを学習するため,SimCLRと呼ばれる自己教師あり学習手法を組み込みました. この学習では,1つの画像に異なるデータ拡張を加えて「ポジティブペア」を作り,似ていない別の画像は「ネガティブペア」として扱います.これにより,データのラベルを使わずに有用な特徴抽出が可能となり,モデルの判別力を高めています.
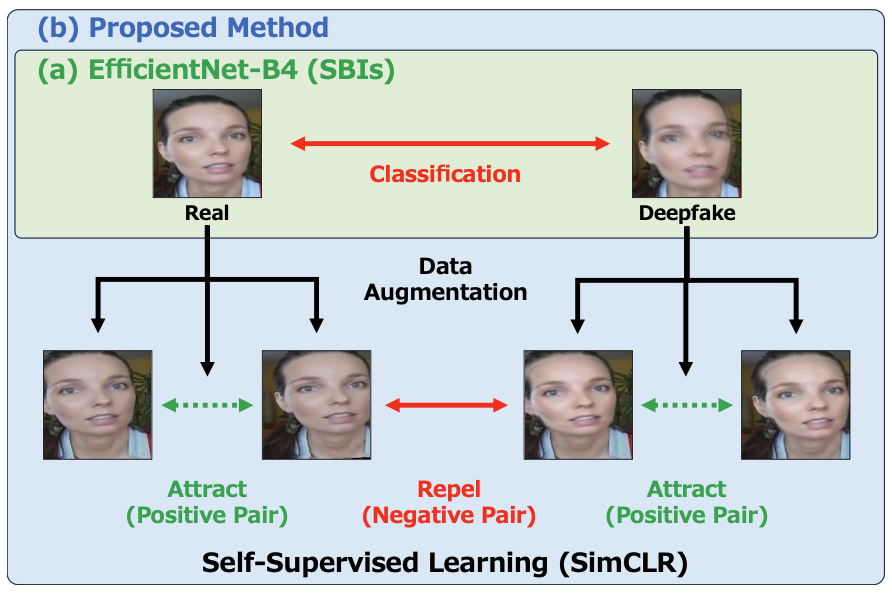
提案手法の流れ
Self-Blended Images(SBIs)による学習データの拡張
学習用のDeepfake画像として「SBIs(Self-Blended Images)」という手法で生成した疑似的な画像を用いています.これにより,より多様なパターンの偽造痕跡を含む画像でモデルを学習させることが可能になり,汎化性能が向上します.
評価実験と結果
FaceForensics++など複数のベンチマークデータセットを用いた比較実験により,提案手法は従来のCNNベースの手法(EfficientNet-B4など)よりも平均AUC(Area Under Curve)で2.44%の精度向上を達成しました.
| 手法 | 平均AUC(%) |
|---|---|
| EfficientNet-B4 | 90.95 |
| ResNet-50 | 88.25 |
| ViT | 83.33 |
| Wave-ViT | 88.84 |
| Proposed Method | 93.39 |
偽造痕跡への注目
アテンションマップを可視化した結果,提案手法はDeepfake画像の境界線など,偽造の兆候が現れやすい部分に的確に注目していることが確認されました.

アテンションマップの可視化例
関連論文
– 高瀬 俊希,山内 悠嗣,``自己教師あり学習を導入したWavelet Vision TransformerによるDeepfake検出の高精度化”,精密工学会誌,vol. 91, no.2, pp.156-162, 2025. link