深層強化学習+画像予測モデル
画像予測モデルを導入した価値関数に基づく深層強化学習
Project Details
- Start : 2022.4
- Collaborator : 加藤誉基
概要
強化学習は観測した現在までの状態における価値を最大化するように学習する.価値とは将来にわたって獲得できる報酬の期待値であるため,先の状態を予測できれば現在の状態のより高い価値を求めることができる.
そこで,本研究では現在の状態のより高い価値を求めるために,価値を計算する際に先の状態を予測する時系列モデルを導入する.先の状態を予測するために,連続した画像の時系列データから次時刻以降に観測されるであろう未来の画像を予測する深層学習モデルを用いる.先の状態を予測し,現在の状態のより高い価値を求めることで,早期に高い報酬が得られることが期待できる.
提案手法
画像予測モデルを導入した価値関数に基づく強化学習を提案
本研究では,画像予測モデルを導入した価値関数に基づく強化学習の手法を提案する.現在の価値と次時刻の価値の差分を正確に求めるため,Qネットワークの損失関数に予測した先の状態の価値を導入する.これにより,エージェントは将来の状態の予測を織り込んだ意思決定が可能となり,単純な即時報酬の最大化ではなく,将来の報酬を見据えた長期的な視点での最適化が促進される.
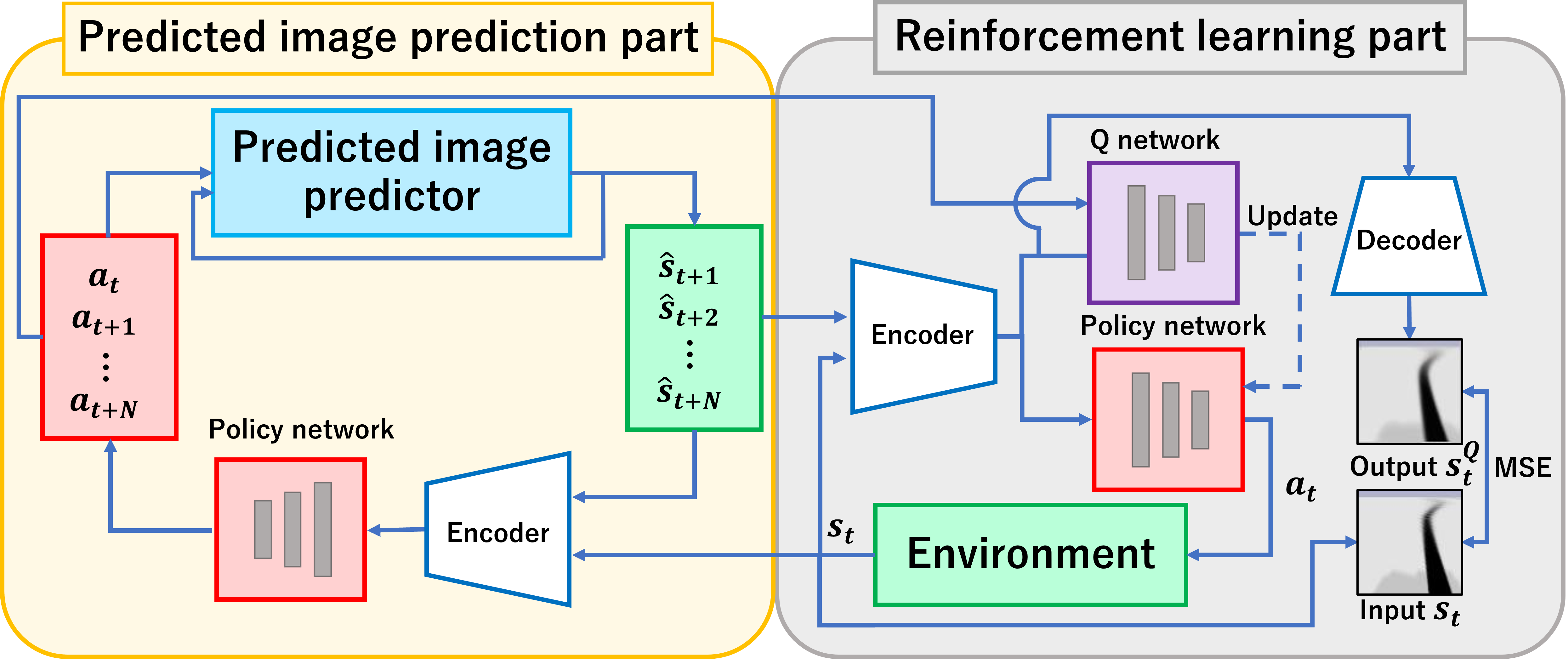
提案手法の流れ
予測画像生成
予測画像生成器にはConvolutional Dynamic Neural Advection(CDNA)を採用する.CDNAは連続した数フレームの画像群と,それらの画像群から観測されるオブジェクトの動きや姿勢などを条件として加え,1フレーム先の予測画像を生成する条件付き予測画像生成器である.
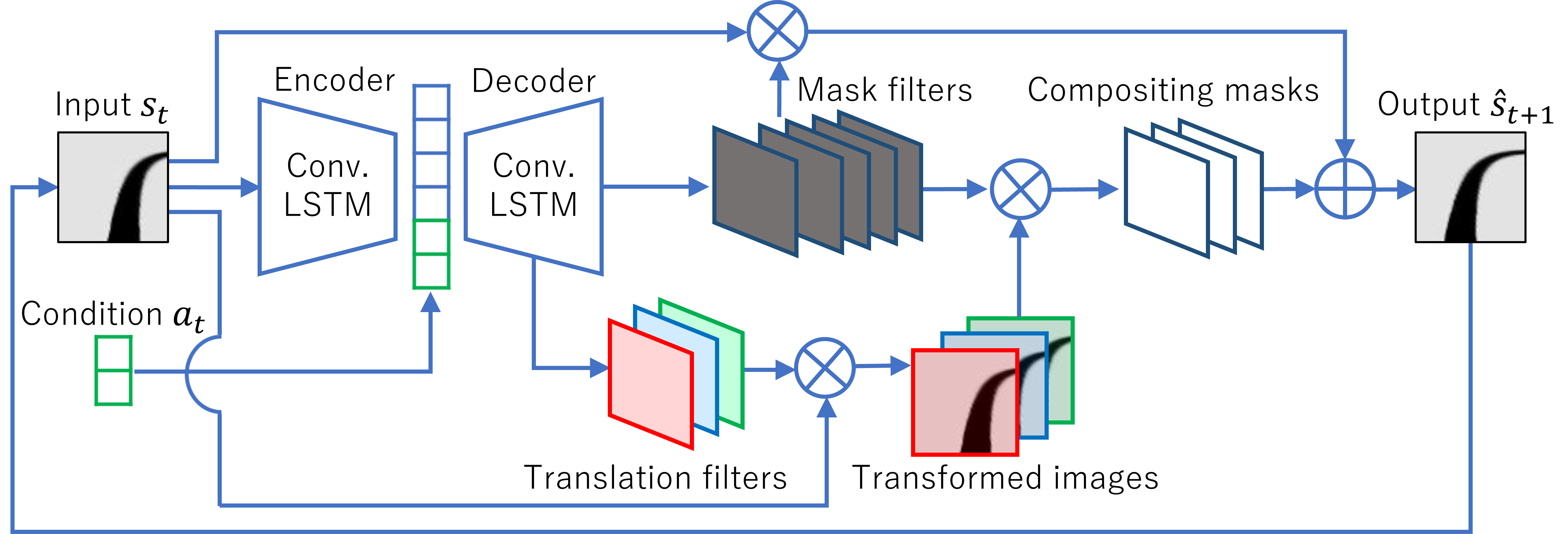
CDNAの概要
評価実験と結果
ライントレースタスク
評価実験では,ライントレースタスクを用いて提案手法の性能を検証した,具体的には,エージェントが異なる予測フレーム数を持つ環境でどのように学習し,報酬がどのように変化するかを比較した.
結果として、適切な予測フレーム数を導入することで,学習の初期段階において高い報酬を獲得できることが確認された.特に,適度な予測フレーム数を設定した場合,学習の安定性が向上し,高い報酬を得るまでの時間が短縮された.一方で,予測フレーム数が過剰に大きい場合,誤差の蓄積が増加し,報酬が低下する傾向が見られた.
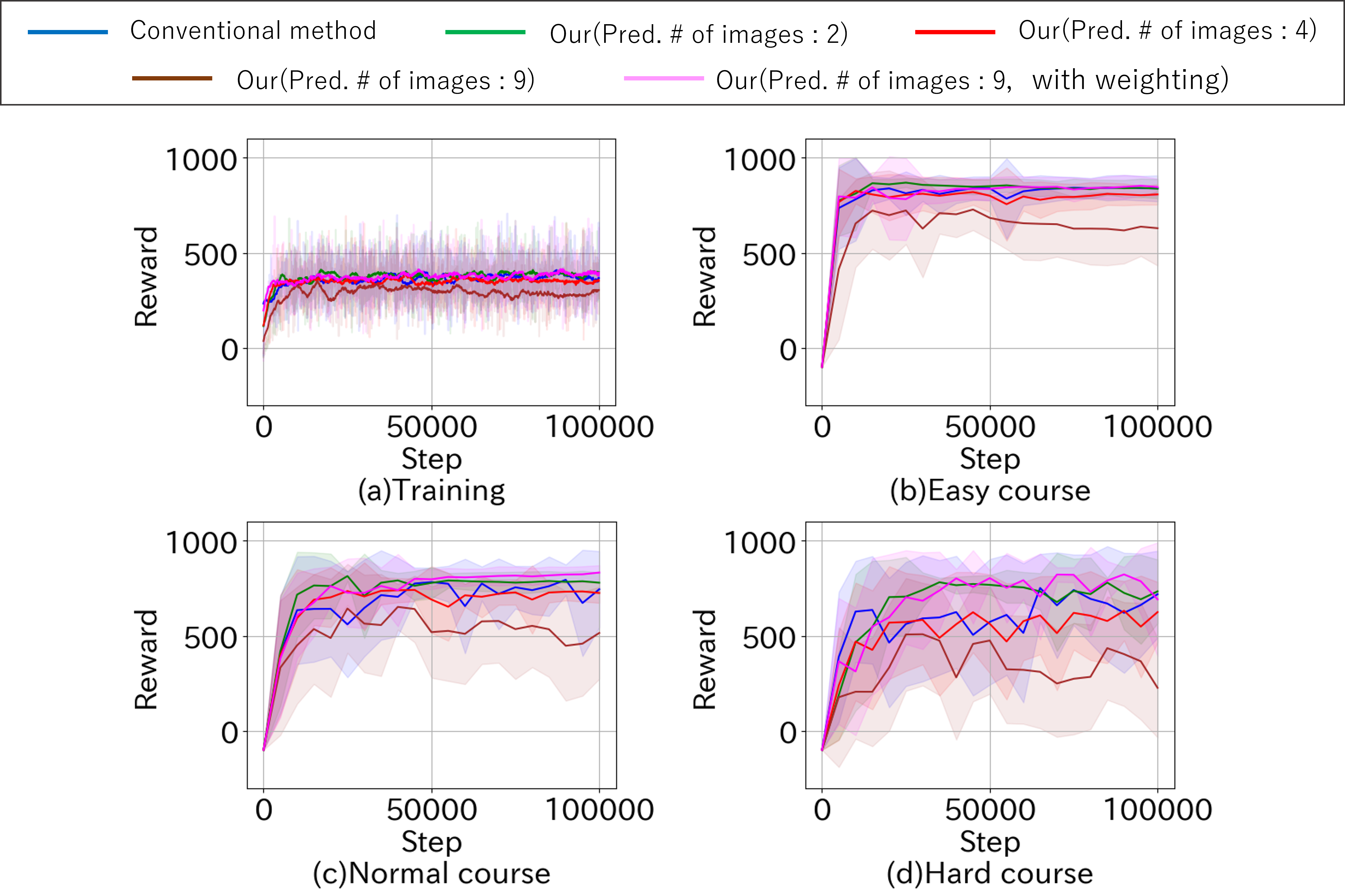
ライントレースタスクの各ステップにおける報酬
カートポールタスク
カートポールタスクにおいても、同様の評価実験を実施した.エージェントが適切な予測フレーム数を選択することで,報酬の向上が確認された.ただし,ライントレースタスクと比較すると,報酬の向上幅には違いがあり,タスクごとに最適な予測フレーム数が異なることが示唆された.
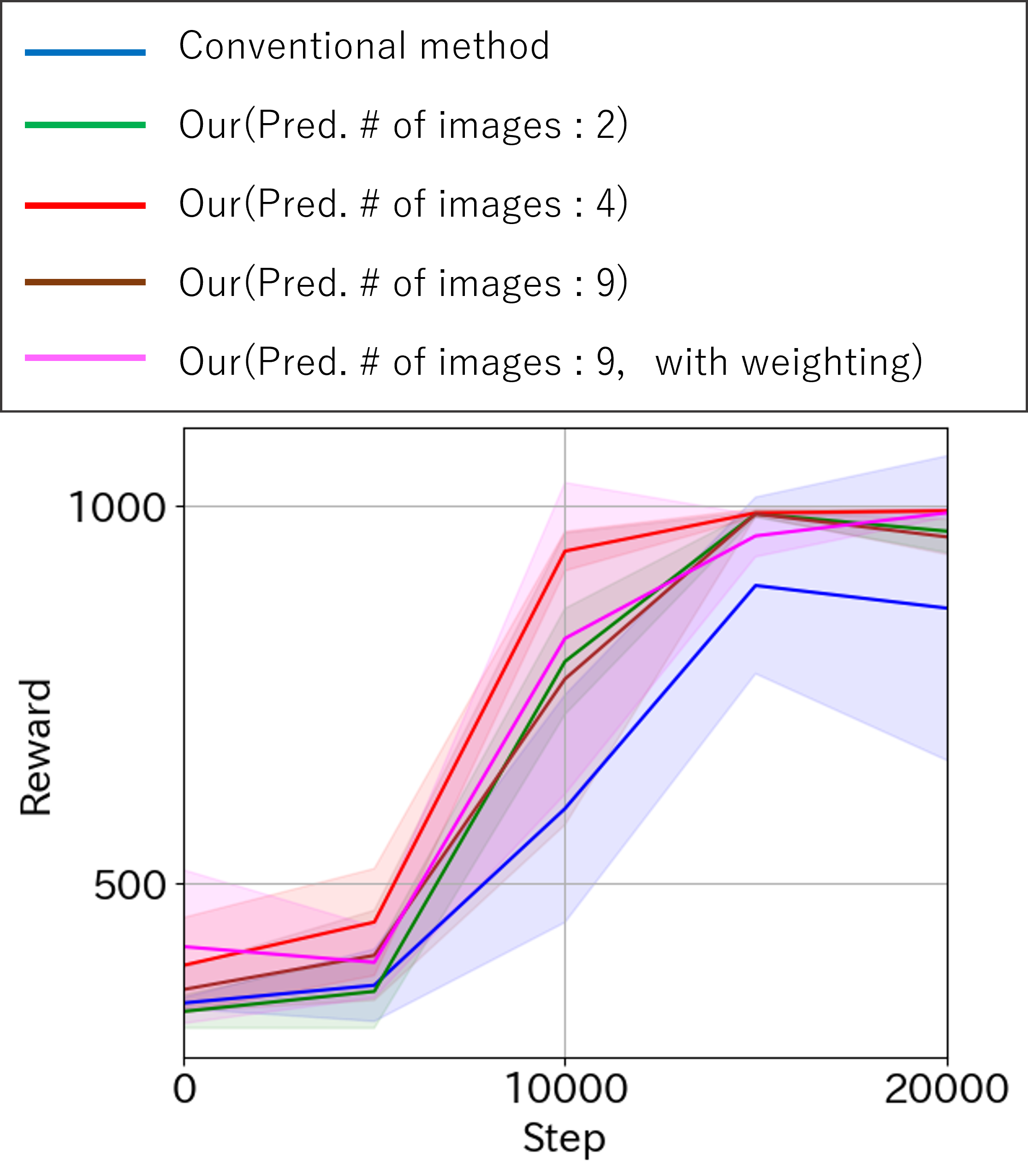
カートポールタスクの各ステップにおける報酬
関連論文
– 加藤 誉基,西片 智広,山内 悠嗣,``画像予測モデルを導入した価値関数に基づく深層強化学習”,精密工学会誌,vol. 91, no.4, pp.518-525, 2025. link